

前言
我在微信公众号上无意中刷到这篇文章,主要内容为对大语言模型约束输出格式会对结果造成的影响,原微信文章说的比较浅,对这篇文章做了一个简洁的介绍,由于之前在做数据处理的时候,在该领域踩了深坑,所以决定对这篇文章进行深入一点的学习。
日前在调用 ChatGLM、DeepSeek 等还没有官方 json
模式约束的模型时,我使用了将格式置于 System Prompt
中的方式,这种方式的生成精准度非常差,一个是生成多样性的问题,还有一个是生成稳定性的问题,我使用了List与JSON两种方式来约束生成,对List方式,我在系统提示词中要求它
each prompt start with number sequence list, end with <EOF>,don't output any other things.
,并给出了 Example
1 | Example: |
在这里我踩了两个坑,一个是
Example,对于信息抽取任务来说,如果给定了部分具体的
Example,部分模型很容易会一定程度上认为是分类任务,然后在输出内容中直接输出我给出的
Example,还有一个情况是不遵循我给出的格式,比如会全部输出完毕后在最后追加
<EOF>,对于 GLM 的 Batch
还会出现非常严重的不稳定情况,比如莫名其妙的在很多输出内容中会先输出with,然后再输出格式化内容,原因未知。
对于 JSON 约束来说,也是在 System Prompt 中进行约束,并给出 Example,这里引用 Kaggle 的 Essay Score 任务来举例,我希望 LLM 对给定论文进行逐条点评,然后输出最终分数,该模式在 ChatGPT 下响应正常,但是在 ChatGLM 、 DeepSeek 、Qwen2 与开源模型的表现就有些差强人意了,一个是这些大模型在输出约束上基本都做到了对 json 本体的约束。但是,模型会出现包括且不限于 1. 在 json 外裹一层 markdown 语法(不稳定复现), 2. 在 json 外输出其他无关内容, 3. 在输出过程中语义理解混乱,在最后 parser 的时候更是让我反复调试。
以上问题日前困扰了我不少,于是这次我看到这篇文章后决定深入了解一下这篇文章所述内容。
论文标题:Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models
论文链接: https://arxiv.org/abs/2408.02442
TLDR
对大模型约束格式化输出,在很多情况下会显著降低大模型推理性能。
摘要与结论
这篇文章研究了这种对生成空间的约束是否会影响LLM的能力,包括推理能力和领域知识理解能力。其评估了在受限于遵循结构化格式与生成自由形式响应的情况下,各种常见任务中的LLM性能表现。
经过一系列研究后得到结论:格式限制下LLM的推理能力显著下降。此外,我们发现更严格的格式约束通常会导致推理任务中的性能退化更大。
受约束的解码(JSON模式),可能会阻碍推理能力并提高分类任务的准确性。较宽松的格式限制通常会改善性能并减少推理任务中的方差。解析错误虽然不是导致性能差异的主要原因,但可以通过纠正提示来缓解。这些发现强调了在LLM应用中平衡格式遵循、推理能力和成本效率的重要性。
论文内容

这篇文章在第一页放的图片,与前言中我所说的Essay Scoring任务中json约束所造成的影响类似,其首先会影响到思维链的推理步骤,在我的论文评分任务中,我要求大模型生成不定长的论文点评列表,并依据这个列表生成最后的得分,但是大模型在推理时总会约束为我给出的Example评价数量,得分偏差很大,实际情况下还出现了评价与得分依据推理差距非常大的情况,如对一篇文章的评价非常高,但最后的得分打了一个1/5。
约束模式
这篇文章介绍了三种约束模式,分别为Constrained Decoding(JSON-Mode)、Format-Restricting Instruction(FRI)、NL-To-Format(NL2Format)
Constrained Decoding(JSON-Mode)
约束解码是限制生成过程中LLMs输出的技术,在生成过程中强制执行预定义的Token空间。
在主流的LLM提供商中都有提供这种模式,比如OpenAI与Gemini API,都将其作为超参的一种,强制约束生成JSON。
Format-Restricting Instruction(FRI)
格式化约束指令引导LLM生成标准化格式的响应,如JSON、XML和YAML,并遵循指定的模式。这些指令确保,生成的输出是否遵循结构化的格式,有助于提取和评估最终答案。这种方法比约束解码更放松,因为它不强制使用预定义的Token空间。
换句话说也就是在给出的Prompt指令来提示大模型如何生成格式化约束,不作为超参提供,不依赖API提供商的JSON生成模式
NL-to-Format(NL2Format)
NL-To-Format是一种Two Step过程,首先给出指令,要求大模型回答问题,然后在下一步的指令中以类似FRI的方式指示其转化为目标格式,该方式将生成(content generation)和格式遵从性(format adherence)解耦,旨在同时提供结构化的输出,并不受限制的发挥自然语言响应能力。
缺点就是需要两轮,无法一次性生成
实验
数据集
该文章总计使用了七个数据集,并将其划分为两个主要任务,一个任务为推理任务,使用了:GSM8K、Last Letter Concatenation、Shuffled Objects,分别为数学问题、字母拼接、初始状态推理最终状态;另一个任务为分类任务,使用了DDXPlus、MultiFin、Sports Understanding、NI-Task 280,分别问医学诊断、金融分类、体育相关构造句子可能与否的分类任务、刻板印象分类任务。
模型
该文章使用了五个模型来做实验:gpt-3.5-turbo-0125、claude-3-haiku-20240307、gemini-1.5-flash、LLaMA-3-8B-Instruct、Gemma-2-9B-Instruct。
吐槽:怎么还是gpt3.5,和后面几个的时间跨度差太大了吧
评价方法
评价指标
由于该文章所述工作有多重任务,所以将其评价指标都进行了区分,对于分类任务(Sports Understanding、DDXPlus、Natural Instruction Task 280 和 MultiFin),该工作使用了accuracy作为主要指标,对于Last Letter Concatenation与GSM8K,则要求精准匹配,必须与答案完全匹配。
Shuffled Objects的评价指标呢....
文本解析器
这篇文章的工作为了将错误格式和生成内容区分开,使用了上级模型来作为评判模型,而不是依赖正则表达式或字符串解析器。
经过其消融实验,以gpt-4-turbo为偏好基准,选取了claude-3-haiku-20240307作为低成本API。
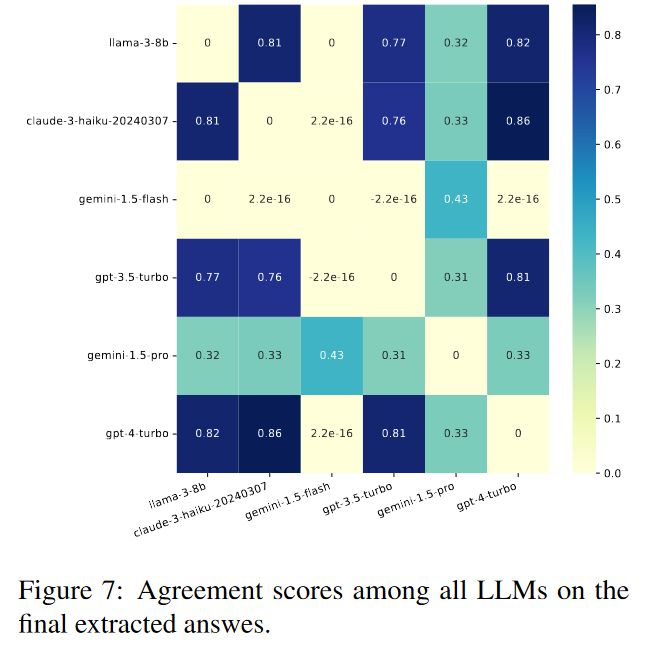
为了选择最佳和低成本的LLM解析器,其从六个数据集中的自然语言格式响应中选择了200个样本,总共为1,200个样本。然后将gpt-4-turbo作为最佳LLM答案解析器作为参考,并在图7中计算了三个LLM候选者:gemini-1.5-flash、claude-3-haiku-20240307和llama-3-8b-instruct的kappa cohen系数。结果表明,claude-3-haiku-20240307与gpt-4-turbo的最高一致性为0.86,其次是llama-3-8b-instruct。
主要结论
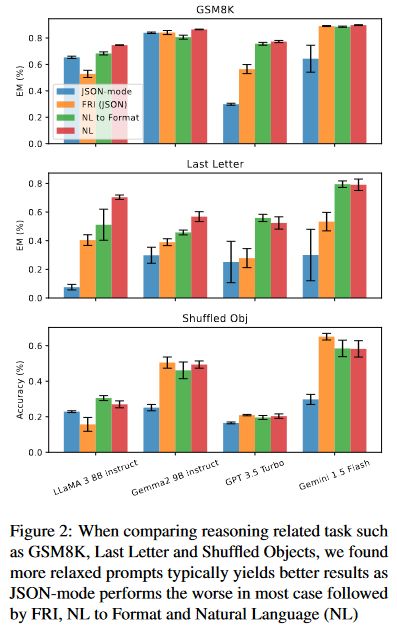 据图二所示的测试结果,JSON模式在Last
Letter任务上的表现明显不如FRI(JSON)。经过检查,发现所有GPT 3.5 Turbo
JSON模式的响应都将“answer”key放在“reason”key之前,导致CoT失效,直接Zero-Shot回答答案而不是Zero-Shot
CoT推理。
据图二所示的测试结果,JSON模式在Last
Letter任务上的表现明显不如FRI(JSON)。经过检查,发现所有GPT 3.5 Turbo
JSON模式的响应都将“answer”key放在“reason”key之前,导致CoT失效,直接Zero-Shot回答答案而不是Zero-Shot
CoT推理。
将NL2Format与不设限NL相对比,在大部分模型与数据集上则表现较为相似,但是NL2Format偶尔会出现生成错误,导致LLaMA3 8B Instruct性能略有下降
这些发现表明,格式限制的范围和实施程度可以显著影响LLM性能,特别是在推理任务中。结构化输出中的Key的顺序以及推理与格式遵守之间的解耦是维持LLM能力并提供结构化响应的重要因素。
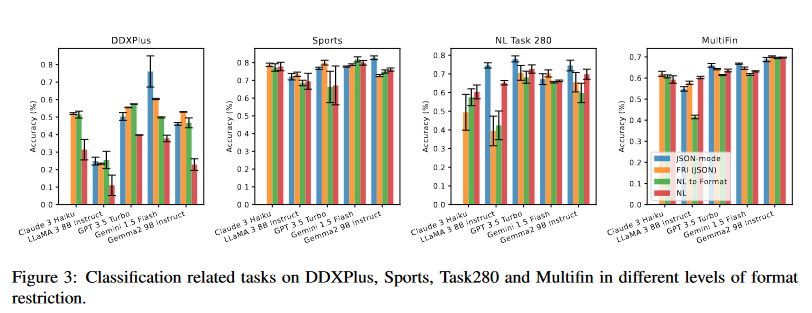
据图3所示的分类任务测试结果,在DDXPlus数据集中,当启用JSON模式时,Gemini 1.5 Flash表现出显著的性能提升。在其他分类数据集中,JSON模式表现则具有竞争性,并且在某些情况下超过了其他三种方法。
该文章作者假设JSON模式通过限制可能的答案来减少答案选择中的错误,从而改善分类任务的表现。相反,自然语言响应可能会引入干扰,导致解析错误。这些发现表明格式化限制对LLM性能的影响取决于任务:
严格的格式限制可能阻碍推理密集型任务,但有助于需要结构化输出的分类任务的准确性。
讨论
对宽松格式限制的影响
该文章作者对LLM提供更为宽松的格式限制,如严格的格式限制会给出特定的schema,例如:
1 | Reply your answer in JSON format with the following schema: { "reason": ..., "answer": ... } |
简化为宽松格式为:
1 | Reply your answer in JSON format. |
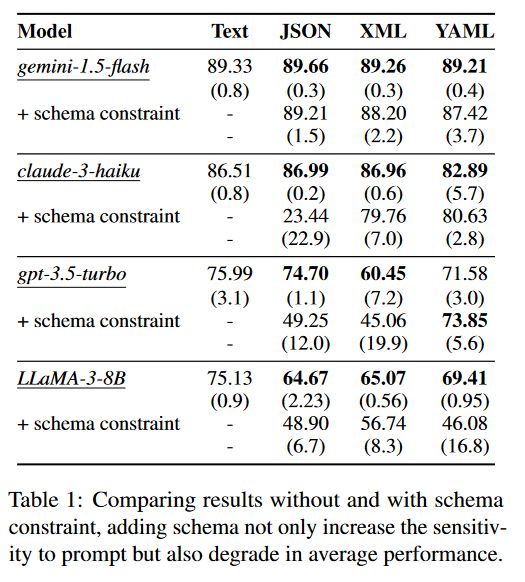
实验结果如上图所示,可以看出Schema限制还是对结果有很大影响的,结果表明,虽然结构化的输出对于下游处理是有益的,但过于严格的模式可能会阻碍LLM的表现,特别是在推理密集型任务中。
这一发现表明,必须在对易于解析、结构化输出的渴望和保留LLM固有推理能力的需求之间取得平衡。从业者可能希望在处理复杂推理任务时考虑使用更宽松的格式限制,同时仍然保持一定程度的结构以促进下游处理。
吐槽:本来格式化输出就是为了解析数据方便下游任务处理,这样还怎么去解析json传给下游任务了
不同格式间的比较
该文章作者还比较了JSON、XML、YAML格式,三种格式遵循不同的语法规则和限制,作者推断每个模型表现不同,例如Claude-3-Haiku使用XML作为工具使用模式
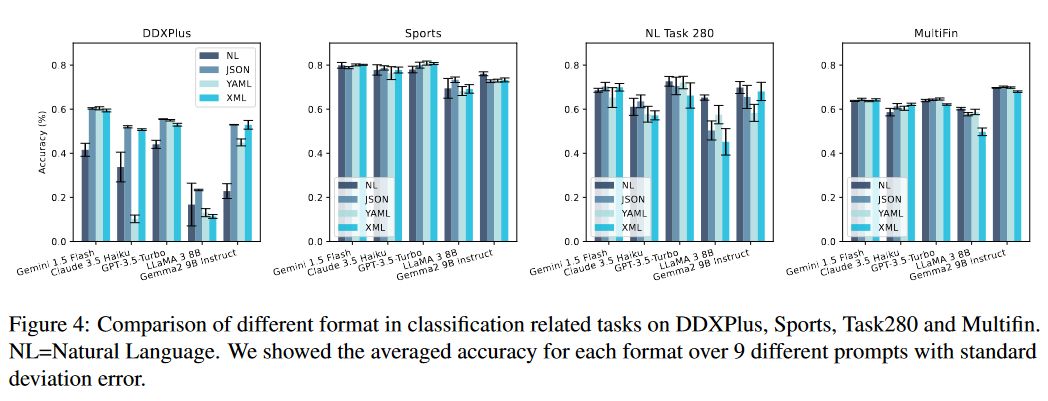
但显然,总体差距不大,在分类任务中,JSON模式的表现要好于文本,因为答案空间受到限制。但在推理相关任务中,JSON模式未能遵守推理顺序,导致最终表现大幅下降。
结构格式与解析错误率
该文章作者假设文本和结构化格式之间的性能差距可能归因于答案提取过程中上级LLM解析错误。但实验结果表明该因素不是决定性错误。
事实上,在三种格式中,Gemini1.5 Flash 和GPT 3.5 Turbo在所有格式中均表现出近乎零的解析失败。在LLaMA 38B设置下,JSON 格式中的Last Letter任务的解析错误率为0.148%,但存在显著的38.15% 的性能差距
这一发现表明,差异并非主要由解析错误引起,而是由于格式限制对LLM推理和生成过程的影响。
在存在解析错误的情况下,通过简单的纠正步骤可以有效地加以缓解。即再加一步,要求模型重新格式化任何带有解析错误的输出,该方法展示了提高结构化输出可靠性的潜力,而不会牺牲特定格式优化的好处。
讲真,这不就是和NL2Format差不多了吗,而且多了一步还大大增加了Token消耗
附录摘要
实验局限性
这项研究有两个主要局限性:
- 由于成本限制,无法在实验中包括更强大的语言模型的结果,例如LLaMA 70B或GPT-4o。这些模型的纳入可能为性能随模型大小和架构的变化提供额外见解。
- 评估数据集虽然多样,但范围有限。更广泛的任务和领域可以提供对所提出方法的有效性和泛化性的更全面评估。
实验成本消耗参考
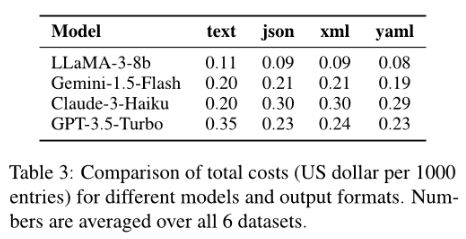
对六个数据集取均值,不同格式下每1000个实体的消耗(美元)
提示工程内容
对于不同的任务,每个任务使用相同的目标,只修改任务描述、格式化描述、Few Shots Example和Question Text,模板如下:

后面的提示工程变形略,作者也没给出不同的变形导致的结果变化结论
写在最后
根据作者所述的这项实验,显然格式化约束对于模型的推理能力有着较大的影响,同时该作者提出,未来的研究应该包括一个更广泛的训练数据范围,该范围包含本地LLM中的各种限制格式的指令。
注意:本文章截止笔记之日2024年8月14日未经过同行评审,为发表在ArXiv上的预印本,请谨慎参考。