

前言
该文是发表在ICLR2024上的一篇会议论文,主要创新内容是使用LLM视为一种Agent,通过交互式操作KG来探索相关实体和关系,进而获取检索信息送入推理,作者团队将其命名为Think-On-Graph,作者团队来自IDEA研究院(非jetbrains的idea)、厦门大学、南加州大学、香港科技大学、微软亚洲研究院。
本文所述主要内容为通过利用LLM的推理能力和专家反馈来实现知识的可追溯性和知识可修正性,后者我认为对于实现一个基于大模型与KG的可信系统来说是一种关键的技术。如果能大幅减少幻觉现象与能提供对思维链过程中对原始数据次级推理及可修订能力,将是一种非常优秀的技术实现。但是与此同时,在阅读本文的过程中,我对于该方法的修订能力是否会进一步引入推理幻觉有一定的怀疑。
论文标题:Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph
论文链接: https://arxiv.org/abs/2307.07697
叠甲:本文只代表本人对该文章的理解和意见,糅杂了我的一些思考进去,我认为的一些潜在方向也在写在里面了,本文所述的翻译和思考内容都不代表原作者的想法和学术意义上的结论,请以本篇论文原文为准。
摘要和结论
对于目前存在的深层次和可信的推理问题,也就是大模型常见的幻觉问题,往往可以通过向LLM引入外部知识图谱来部分解决,该文作者团队提出了一种集成范式“
本文所述的方法优势:
- 与LLM相比,ToG 具有更强的深层推理能力
- ToG 能够利用 LLM 的推理能力和专家反馈来实现知识可追溯性和知识可修正性
- ToG 提供了一个灵活的插拔框架,适用于不同的 LLM、KG 和提示策略,而无需任何额外的训练成本
- ToG 使用小 LLM 模型在某些情况下可以超过 GPT-4 等大 LLM,从而降低了 LLM 部署和应用的成本。
实验结果表面,与现有基于微调的方法和提示方法相比,ToG可以在没有额外训练成本的情况下表现更好,缓解了LLM的幻觉问题
简介
LLMs利用对大量文本语料库进行预训练的技术来生成连贯且上下文适应的响应,但是当面临需要深入到深层次或者具有负责任性质的可信复杂知识推理任务时,LLMs存在重大局限性,其无法提供准确的答案来回答超出预训练阶段所包含的知识的专业问题,或者需要长程逻辑链和多跳知识推理的问题。其次,LLMs缺乏责任性、可解释性、透明性,进一步引发了对LLMs会产生幻觉和有害文本风险的担忧。第三,训练LLMs通常成本很高,耗时很长,使其保持知识更新变得困难。
为了解决上述问题,最有希望且快捷的解决办法就是在推理过程中把外部知识塞进LLM里面去,但是如何将外部知识融入进去,作者提出使用知识图谱,发挥其结构化、明确和可编辑的知识表示形式,为缓解LLM的局限性提供了补充策略。
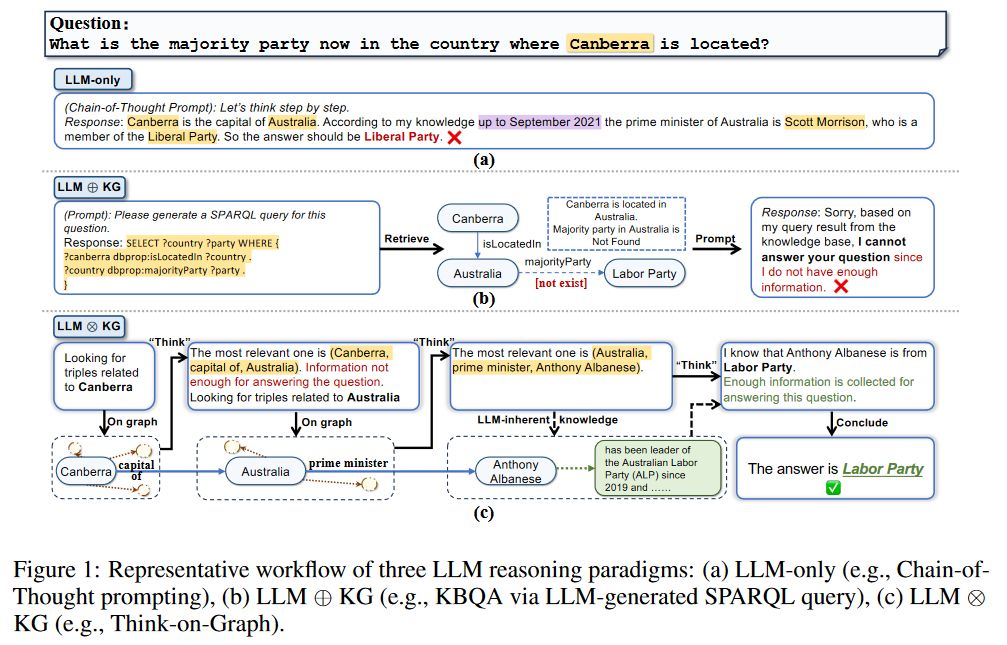
近年来探索使用知识图谱作为外部知识源来减轻LLM幻觉的方法都遵循一种从知识图谱中检索信息,来进行相应的增强提示,并将增强提示馈送给LLM,参照图1(b),本问作者提出该范式为
于是在上述考虑的基础上,本文作者提出了一种新的范例,命名为
给定一个输入问题,ToG先识别初始实体,然后迭代调用LLM通过探索(通过"on graph"步骤查找KG中的相关三元组)和推理(通过"think"步骤决定最相关的三元组)从KG中不断检索出三元组,直到通过集束搜索处理的Top-N个推理路径足够回答问题(由思考中的LLM自行判断),或者达到预定义的最大搜索深度阈值。
ToG的优势可以简要概括为:(1)深度推理:ToG从知识图谱中提取多样且多步的推理路径,作为LLM推理的基础,增强LLM在知识密集型任务中的深度推理能力;(2)负责可信的推理:明确可编辑的推理路径提高了LLM推理过程中的可解释性,并使模型输出的来源得以追踪和纠正;(3)灵活性和效率:a)ToG是一个开箱即用的框架,无缝适用于多种LLM和知识图谱。b)在ToG框架下,可以通过知识图谱频繁更新知识,无需使用LLM进行昂贵且缓慢的知识更新。c)ToG提升了小LLM的推理能力(?),使其具有与大LLM竞争的能力。
方法
ToG通过要求LLM在知识图谱上执行集束搜索来实现本文所述范式。其会提示LLM迭代地在知识图谱上探索多个可能的推理路径,直到LLM根据当前的推理路径确定问题可以回答为止。每次迭代后,ToG都会不断更新维护问题的前N条推理路径
初始化图搜索
给定一个问题,ToG利用LLM在知识图谱上定位推理路径的初始实体,此阶段可以视为对Top-N个推理路径P的初始化。ToG首先提示LLM自动提取问题中的主题实体,并擎获得Top-N个主题实体
探索
在
在第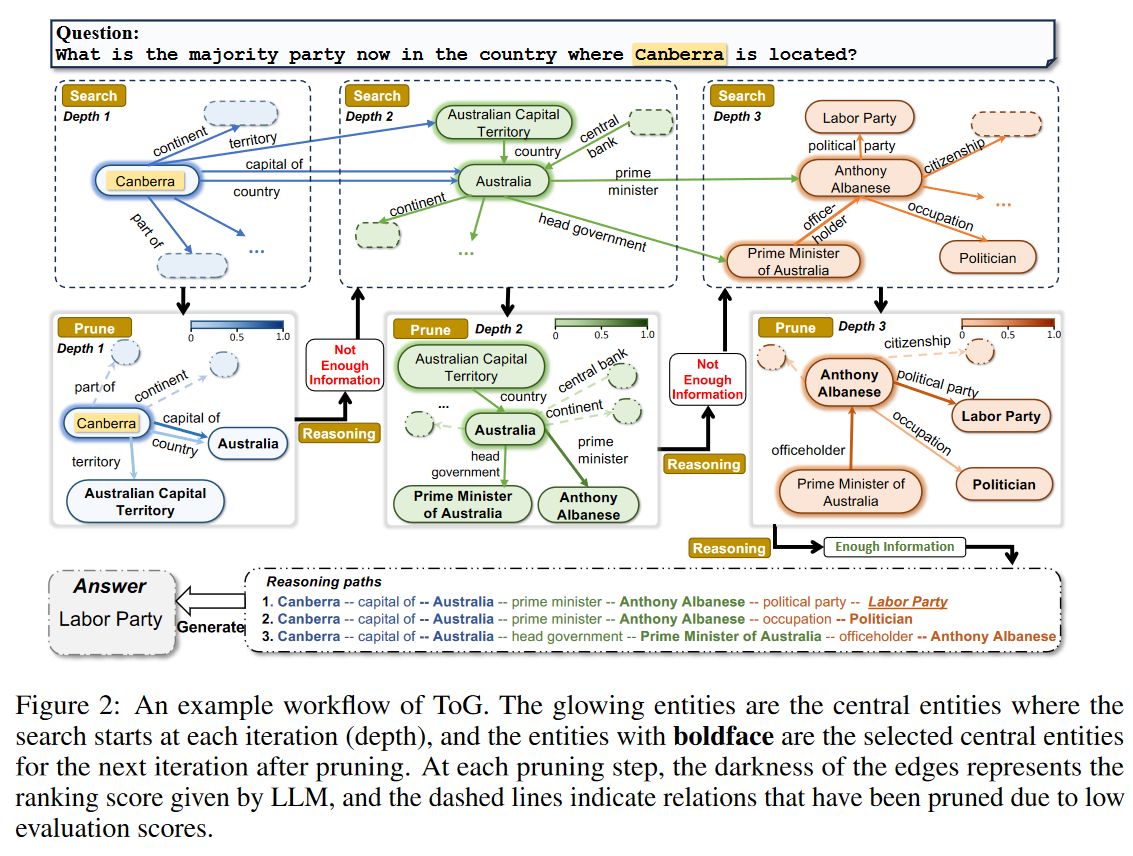 ### 关系探索 关系探索从
### 关系探索 关系探索从
搜索
在第
附录E.1: 1
2
3
4
5
6
7PREFIX ns: <\protect\vrule width0pt\protect\href{http://rdf.freebase.com/ns/}{http://rdf.freebase.com/ns/}>
SELECT ?relation
WHERE { ns:mid ?relation ?x . }
PREFIX ns: <\protect\vrule width0pt\protect\href{http://rdf.freebase.com/ns/}{http://rdf.freebase.com/ns/}>
SELECT ?relation
WHERE { ?x ?relation ns:mid . }
附录E.2: 1
2
3
4
5
6
7PREFIX ns: <\protect\vrule width0pt\protect\href{http://rdf.freebase.com/ns/}{http://rdf.freebase.com/ns/}>
SELECT ?tailEntity
WHERE { ns:mid ns:relation ?tailEntity . }
PREFIX ns: <\protect\vrule width0pt\protect\href{http://rdf.freebase.com/ns/}{http://rdf.freebase.com/ns/}>
SELECT ?tailEntity
WHERE { ?tailEntity ns:mid ns:relation . }
E.1中的查询: 这个查询用于获取某个实体(例如Canberra)相关的所有关系(无论是入边还是出边)。查询分为两部分:
- 第一部分:
SELECT ?relation WHERE { ns:mid ?relation ?x . },这是查找该实体(ns:mid,比如Canberra)作为出发点,连接到其他实体(?x)的关系。 - 第二部分:
SELECT ?relation WHERE { ?x ?relation ns:mid . },这是查找其他实体(?x)通过某个关系,连接到该实体(ns:mid)的情况。
- 第一部分:
E.2中的查询: 这个查询用于获取某个实体的尾实体。查询分为两部分:
- 第一部分:
SELECT ?tailEntity WHERE { ns:mid ns:relation ?tailEntity . },这是查找当前实体通过某个关系,连接到的尾实体。 - 第二部分:
SELECT ?tailEntity WHERE { ?tailEntity ns:mid ns:relation . },这是查找尾实体与当前实体通过某个关系连接的情况。
- 第一部分:
剪枝
当我们从关系搜索中获得了候选关系集
附录E.3.1
1 | Please retrieve k relations (separated by semicolon) that contribute to the question and rate their contribution on a scale from 0 to 1 (the sum of the scores of k relations is 1). |
该Prompt要求模型从候选关系集中选择k个最相关的关系(用分号分隔),并为这些关系的贡献进行评分。评分的范围是0到1,所有k个关系的评分总和必须是1。这表示模型需要对这些关系的重要性进行排序和量化。
- In-Context Few-shot: 这是使用“few-shot”学习方法,在上下文中给出一些例子,让模型根据这些例子去推断。这种方法可以帮助模型更好地理解问题和上下文,提升其推理能力。
- Q: {Query}:
这里的
{Query}表示用户输入的问题,也就是模型需要解答的问题。这个问题可以是和知识图谱推理相关的,例如一个复杂的查询任务。 - Topic Entity: {Topic Entity}:
Topic Entity是问题中的主题实体,即推理任务的核心实体。模型要基于这个实体展开推理和搜索相关关系。 - Relations: {list of relations}:
Relations是候选关系集,即。模型需要从中选择最相关的k个关系,并对它们进行打分。 - A:: 这是模型生成答案的地方。根据上面的提示,模型会输出k个最相关的关系,并为每个关系打分。
也许不用chat的模型更好一些?
在执行上述两种探索之后,重新构建了全新的Top-N推理路径P,每个路径长度增加了1,每次剪枝最多需要N次LLM调用(烧钱啊)
推理
他通过探索过程获得当前推理路径P后,提示LLM评估当前推理路径是否足以生产答案,如果评估结果为正面,则提示LLM使用图2所示的查询作为输入的推理路径来生成答案。
评估的提示E.3.3:
1 | Given a question and the associated retrieved knowledge graph triples (entity, relation, entity), you are asked to answer whether it’s sufficient for you to answer the question with these triples and your knowledge (Yes or No). |
- 任务说明:这部分提示LLM根据给定的问题和相关的知识图谱三元组(实体、关系、实体),判断这些三元组是否足够支持模型回答问题。
- 核心问题:模型被要求回答一个简单的"Yes"或"No"问题,具体来说,就是当前推理路径是否已经包含了足够的信息来解答问题。
- In-Context Few-shot:在提示中,使用了上下文少量示例(Few-shot learning)来帮助模型做出判断。这通常通过给出类似的例子,帮助模型更好地理解问题和所需的推理。
- Q:
{Query}:
{Query}是实际问题,模型需要根据这个问题进行判断。 - Knowledge triples: {Explored
Paths}:
{Explored Paths}表示当前已经探索到的推理路径中的知识图谱三元组。模型需要根据这些三元组来判断它们是否足以回答问题。 - A::这是模型的回答部分,模型会给出“是(Yes)”或者“否(No)”。
生成的提示E.3.4:
1 | Given a question and the associated retrieved knowledge graph triples (entity, relation, entity), you are asked to answer the question with these triples and your own knowledge. |
- 任务说明:这部分提示LLM在给定问题的基础上,根据知识图谱三元组和模型的知识生成答案。换句话说,当评估认为推理路径足够时,模型就可以使用这些路径以及其固有的语言能力来生成最终答案。
- 核心任务:模型现在不再是判断信息是否足够,而是要求生成基于这些三元组的具体答案。
- In-Context Few-shot:同样,这里使用上下文少量示例的方式来帮助模型理解如何利用三元组生成答案。
- Q:
{Query}:
{Query}依然是问题本身。 - Knowledge triples: {Explored
Paths}:
{Explored Paths}是当前推理路径中的三元组。这些三元组将作为推理的基础,模型需要利用它们生成问题的答案。 - A::这里模型将生成具体的答案,而不再是简单的“是”或“否”。
已经通过探索过程获得了当前的推理路径
这个过程体现了一种两步式的推理验证和生成机制:
- 评估路径:先判断当前推理路径是否足够支持回答问题。这确保了生成的答案是基于足够信息的,而不是盲目生成。
- 生成答案:在评估通过后,模型将基于推理路径和问题生成答案。
通过这种方式,模型在推理路径的基础上做出合理的判断,并利用这些路径生成更加准确和合理的答案。